The Co-mentions method details entities, topics, and sources identified in chunks that match the query criteria.Documentation Index
Fetch the complete documentation index at: https://docs.bigdata.com/llms.txt
Use this file to discover all available pages before exploring further.
When do chunks match the query criteria?
When do chunks match the query criteria?
Chunks matched the query criteria if the query filters matched the chunk or the document’s headline.Check the page Query filters to see all available filters.
- API
- Python SDK
Co-mentions return the most detected entities and topics.The output is an object containing the most detected entities including entity id, total chunks count and total headlines count:The output is an object containing the most detected topics including topic id, total chunks count and total headlines count:
Connected Entities
Use/v1/search/co-mentions/entities to get the most detected entities among these entity categories:placescompaniesorganizationspeopleproductsconcepts
curl -X POST 'https://api.bigdata.com/v1/search/co-mentions/entities' \
-H 'Content-Type: application/json' \
-H 'X-API-KEY: <your-api-key>' \
--data '{
"query": {
"filters": {
"keyword": {
"any_of": [
"tesla"
]
},
"entity": {
"any_of": [
"228D42"
]
}
},
"limit": 10
}
}'
"results": {
"places": [],
"companies": [
{
"id": "228D42",
"total_chunks_count": 61206,
"total_headlines_count": 20776
},
{
"id": "DD3BB1",
"total_chunks_count": 42786,
"total_headlines_count": 25534
},
{
"id": "0157B1",
"total_chunks_count": 28564,
"total_headlines_count": 0
},
{
"id": "12E454",
"total_chunks_count": 27847,
"total_headlines_count": 5980
},
{
"id": "D8442A",
"total_chunks_count": 26433,
"total_headlines_count": 8461
},
{
"id": "E09E2B",
"total_chunks_count": 25728,
"total_headlines_count": 8376
},
{
"id": "4A6F00",
"total_chunks_count": 22327,
"total_headlines_count": 0
}
],
"organizations": [],
"people": [],
"products": [
{
"id": "39E5EB",
"total_chunks_count": 10157,
"total_headlines_count": 0
}
],
"concepts": [
{
"id": "C4F920",
"total_chunks_count": 34175,
"total_headlines_count": 19545
},
{
"id": "FE1757",
"total_chunks_count": 13740,
"total_headlines_count": 5795
},
{
"id": "38918B",
"total_chunks_count": 0,
"total_headlines_count": 5753
},
{
"id": "168FE8",
"total_chunks_count": 0,
"total_headlines_count": 9884
}
]
}
Connected Topics
Use/v1/search/co-mentions/topics to get the most detected topics.curl -X POST 'https://api.bigdata.com/v1/search/co-mentions/topics' \
-H 'Content-Type: application/json' \
-H 'X-API-KEY: <your-api-key>' \
--data '{
"query": {
"filters": {
"keyword": {
"any_of": [
"tesla"
]
},
"entity": {
"any_of": [
"228D42"
]
}
},
"limit": 10
}
}'
"results": {
"topics": [
{
"id": "business,stock-prices,stock-price,gain,",
"total_chunks_count": 5880,
"total_headlines_count": 2298
},
{
"id": "business,stock-prices,stock-price,loss,",
"total_chunks_count": 5445,
"total_headlines_count": 2050
},
{
"id": "business,indexes,index-value,gain,",
"total_chunks_count": 1574,
"total_headlines_count": 196
},
{
"id": "business,indexes,index-value,loss,",
"total_chunks_count": 1351,
"total_headlines_count": 210
},
{
"id": "business,earnings,earnings,,",
"total_chunks_count": 1238,
"total_headlines_count": 1268
},
{
"id": "business,products-services,product-release,,",
"total_chunks_count": 412,
"total_headlines_count": 0
},
{
"id": "business,stock-picks,stock-pick,buy,",
"total_chunks_count": 295,
"total_headlines_count": 0
},
{
"id": "business,partnerships,partnership,,",
"total_chunks_count": 263,
"total_headlines_count": 0
},
{
"id": "business,labor-issues,layoffs,,",
"total_chunks_count": 251,
"total_headlines_count": 276
},
{
"id": "society,legal,legal-issues,,",
"total_chunks_count": 220,
"total_headlines_count": 210
},
{
"id": "business,earnings,earnings-estimate,,",
"total_chunks_count": 0,
"total_headlines_count": 392
},
{
"id": "economy,foreign-exchange,currency-rate,,",
"total_chunks_count": 0,
"total_headlines_count": 428
},
{
"id": "business,stock-prices,stock-price,,",
"total_chunks_count": 0,
"total_headlines_count": 316
}
]
}
Co-mentions return the most detected entities, topics, and sources, sorted by volume and grouped as follows:Output:It is also possible to work with comentions as a dictionary by using the method Output: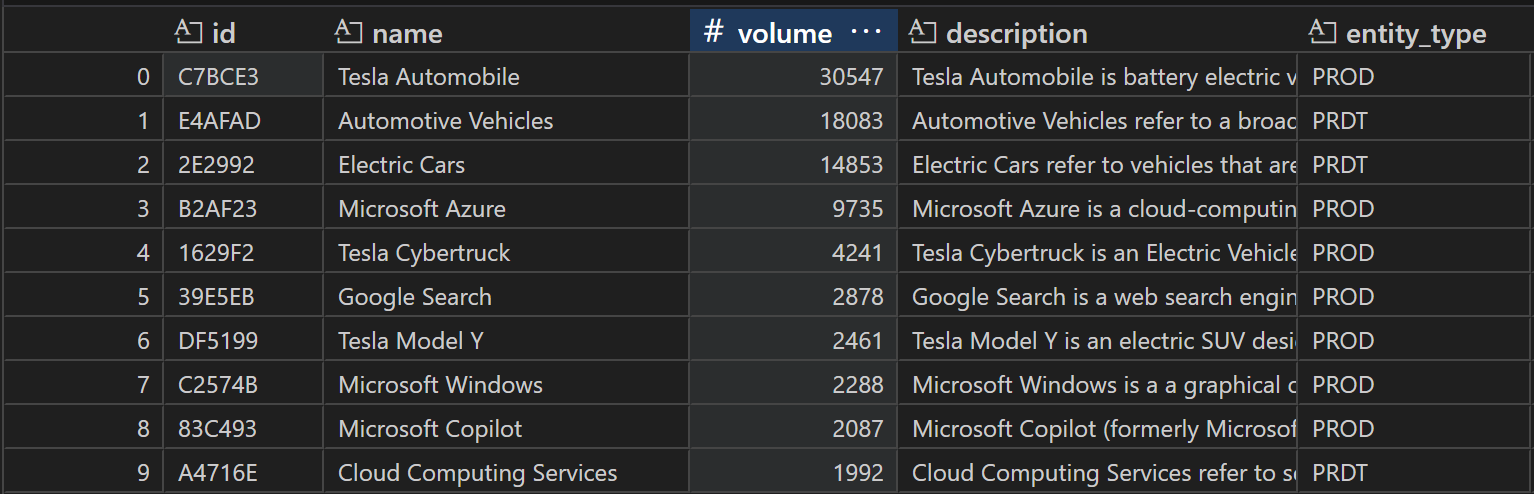
companies: list[bigdata_client.models.entities.Company]concepts: list[bigdata_client.models.entities.Concept]languages: list[bigdata_client.models.languages.Language]organizations: list[Union[bigdata_client.models.entities.Organization,bigdata_client.models.entities.OrganizationType]]places: list[Union[bigdata_client.models.entities.Place,bigdata_client.models.entities.Facility,bigdata_client.models.entities.Landmark]]products: list[Union[bigdata_client.models.entities.Product,bigdata_client.models.entities.ProductType]]sources: list[bigdata_client.models.sources.Source]topics: list[bigdata_client.models.topics.Topic]
from bigdata_client import Bigdata
from bigdata_client.query import Entity, Keyword
MICROSOFT = "228D42"
bigdata = Bigdata()
search = bigdata.search.new(query=(Entity(MICROSOFT) | Keyword("tesla")))
co_mentions = search.get_comentions()
for co_mention in co_mentions:
print(co_mention)
('companies', [Company(id='DD3BB1', name='Tesla Inc.', volume=105282, description='Tesla Inc. (formerly Tesla Motors Inc.) is a California-based company that designs, manufactures and sells electric cars and electric vehicle powertrain components. The company was incorporated on July 1, 2003.', entity_type='COMP', company_type='Public', country='United States', sector='Consumer Goods', industry_group='Automobiles', industry='Automobiles', ticker='TSLA', webpage='http://www.tesla.com', isin_values=['AU0000110991', 'BRTSLABDR008', 'CA88162R1091', 'TH0150120507', 'TH0809121906', 'US88160R1014'], cusip_values=['88160R101', '88162R109', 'P0R67N814', 'Y100G4451', 'Y49876124'], sedol_values=['B3XFVH6', 'B616C79', 'BMGDFF6', 'BMVM8M6', 'BNC31L5', 'BNQS8Z9', 'BYMMQ03'], listing_values=['BVMF:TSLA34', 'XBKK:TSLA80', 'XETR:TL0', 'XFRA:TL0', 'XLON:0R0X', 'XNAS:TSLA']), Company(id='228D42', name='Microsoft Corp.', volume=92441, description='Microsoft Corp., is an American multinational software corporation headquartered in Redmond, Washington that develops, manufactures, licenses, and supports a wide range of products and services related to computing. The company was incorporated on June 25, 1981.', entity_type='COMP', company_type='Public', country='United States', sector='Technology', industry_group='Software', industry='Software', ticker='MSFT', webpage='http://www.microsoft.com', isin_values=['AU0000004574', 'CA59516M1041', 'TH0150121109', 'US5949181045'], cusip_values=['594918104', '59516M104', 'P0R682363', 'Q3R79Y132', 'Y49876181'], sedol_values=['2588173', '2668398', '5925205', '6257866', 'BGHHBL3', 'BPGZV88', 'BPLLQL9'], listing_values=['NEOE:MSFT', 'XHKG:04338', 'XHKG:4338', 'XMEX:MSFT', 'XNAS:MSFT', 'XNMS:MSFT']), Company(id='E09E2B', name='NVIDIA Corp.', volume=8983, description='NVIDIA Corp., incorporated in April 1993, designs, develops, and markets three dimensional (3D) graphics processors and related software. The Company offers products that provides interactive 3D graphics to the mainstream personal computer market as well as system on a chip units for the mobile computing and automotive market.', entity_type='COMP', company_type='Public', country='United States', sector='Technology', industry_group='Semiconductors', industry='Semiconductors', ticker='NVDA', webpage='http://www.nvidia.com', isin_values=['AU0000079733', 'CA67080A1093', 'TH0150121000', 'TH0809121807', 'TH8483122603', 'US67066G1040'], cusip_values=['67066G104', '67080A109', 'P0R67N707', 'Q3R79Y306', 'Y100G4386', 'Y49876199', 'Y985HU589'], sedol_values=['2379504', 'B10S3Q7', 'BJP50T1', 'BMGDF90', 'BP6LB42', 'BPLLR27', 'BVF8ZL1'], listing_values=['XBKK:NVDA80', 'XETR:NVD', 'XFRA:NVD', 'XFRA:NVDG', 'XLOM:0R1I', 'XNAS:NVDA']), Company(id='4A6F00', name='Alphabet Inc.', volume=6696, description='Alphabet Inc. (formerly Google Inc.) operates as a technology conglomerate, providing various services for people and businesses. It was founded on September 4, 1998. After a reorganization of Google on October 2, 2015, Alphabet Inc. became the parent company of Google and several former Google subsidiaries.', entity_type='COMP', company_type='Public', country='United States', sector='Technology', industry_group='Internet Services', industry='Internet Services', ticker='GOOGL', webpage='http://www.abc.xyz', isin_values=['ARDEUT116159', 'AU0000079774', 'BRGOGLBDR001', 'BRGOGLBDR019', 'CA02080K1049', 'TH0150120903', 'US02079K1079', 'US02079K2069', 'US02079K3059', 'US38259P2011', 'US38259P3001', 'US38259P4090'], cusip_values=['02079K107', '02079K206', '02079K305', '02080K104', '38259P201', '38259P300', '38259P409', 'P0R684351', 'Q3R79Y397', 'Y49876173'], sedol_values=['B043K04', 'BJP50X5', 'BL25KS7', 'BNC31T3', 'BPLLP90', 'BYV1PK4', 'BYV1PL5', 'BYVY8G0', 'BYY88Y7'], listing_values=['BVMF:GOGL34', 'BVMF:GOGL35', 'CHIA:TCXGOG', 'NEOE:GOOG', 'XMEX:GOOGL', 'XNAS:GOOG', 'XNAS:GOOGL', 'XNMS:GOOG']), Company(id='12E454', name='Meta Platforms Inc.', volume=6124, description='Meta Platforms Inc. (formerly Facebook Inc.) is an American multinational technology company. The company engages in the development of social media applications for people to connect through mobile devices, personal computers, and other surfaces. The company was incorporated on July 29, 2004 as TheFacebook Inc.', entity_type='COMP', company_type='Public', country='United States', sector='Technology', industry_group='Internet Services', industry='Internet Services', ticker='META', webpage='http://meta.com', isin_values=['AU0000004558', 'BRM1TABDR009', 'CA59101A1012', 'TH0150121505', 'TH0809121609', 'TH0842120303', 'US30303M1027'], cusip_values=['30303M102', '59101A101', 'P0R67N699', 'Q3R79Y140', 'Y100G4360', 'Y476JC249', 'Y49876215'], sedol_values=['B7TL820', 'BGHHCJ8', 'BMCJRW9', 'BMGDF78', 'BNZJ4X3', 'BR1WCC9', 'BSJC7H8', 'BVF8ZC2'], listing_values=['NEOE:MVRS', 'XBKK:META80', 'XETR:FB2A', 'XFRA:FB2A', 'XLON:0QZI', 'XNAS:META', 'XWBO:META']), Company(id='0157B1', name='Amazon.com Inc.', volume=5591, description='Amazon.com Inc. is a multinational technology company focusing in e-commerce, cloud computing, and artificial intelligence. The company was incorporated on July 5, 1994.', entity_type='COMP', company_type='Public', country='United States', sector='Consumer Services', industry_group='General Retailers', industry='Internet & Direct Marketing Retail', ticker='AMZN', webpage='http://www.amazon.com', isin_values=['AU0000048530', 'CA02315E1051', 'TH0150121307', 'TH0809121401', 'TH0842120105', 'US0231351067'], cusip_values=['023135106', '02315E105', 'P0R686174', 'Q3R79Y207', 'Y100G4345', 'Y476JC223', 'Y49876231'], sedol_values=['2000019', '2436368', 'B01YWR1', 'B58WM62', 'BJ9K865', 'BNC31M6', 'BR1WCN0', 'BS7ZCZ2', 'BVBDDH2'], listing_values=['XBKK:AMZN80', 'XBOG:AMZN', 'XLIM:AMZN', 'XMEX:AMZN', 'XNAS:AMZN', 'XNMS:AMZN']), Company(id='D8442A', name='Apple Inc.', volume=4193, description='Apple Inc. (formerly Apple Computer Inc.), incorporated on January 03, 1977, designs, manufactures, and markets mobile communication and media devices, personal computing products, and portable digital music players worldwide.', entity_type='COMP', company_type='Public', country='United States', sector='Technology', industry_group='Computer Hardware', industry='Computer Hardware', ticker='AAPL', webpage='http://www.apple.com', isin_values=['AU0000004491', 'CA03785Y1007', 'TH0150120408', 'TH0809121500', 'US0378331005'], cusip_values=['037833100', '03785Y100', 'P0R684385', 'Q3R79Y108', 'Y100G4352', 'Y49876132'], sedol_values=['2046251', 'BGL1W96', 'BNC31R1', 'BPXWT99', 'BVBDDG1'], listing_values=['XBKK:AAPL80', 'XNAS:AAPL']), Company(id='UWCVKI', name='OpenAI Inc.', volume=3386, description='OpenAI Inc. is a non-profit artificial intelligence research company whose goal is to advance digital intelligence in the way that is most likely to benefit humanity. The company was incorporated on the 8th of December, 2015.', entity_type='COMP', company_type='Private', country='United States', sector='Technology', industry_group='Software', industry='Software', ticker=None, webpage='http://www.openai.com', isin_values=None, cusip_values=None, sedol_values=None, listing_values=None), Company(id='88701C', name='BYD Co. Ltd.', volume=1949, description='BYD Co Ltd. engages in the research, development, manufacture, and sale of rechargeable batteries and photovoltaic business. The company was founded on February 10, 1995, and is headquartered in Shenzhen, China.', entity_type='COMP', company_type='Public', country='China', sector='Consumer Goods', industry_group='Automobiles', industry='Automobile Manufacturers', ticker='002594', webpage='http://www.bydglobal.com', isin_values=['CNE100000296', 'CNE100001526', 'SGXE33900452', 'TH0150120200', 'TH0809122201', 'US05606L1008'], cusip_values=['05606L100', 'Y100G4428', 'Y1023R104', 'Y1023R120', 'Y1045E115', 'Y498QL112', 'Y68842197'], sedol_values=['6536651', 'B0WVS95', 'B3DTK60', 'B466322', 'B5T4MN4', 'BD5CQ69', 'BLBLXG5', 'BMGDF67', 'BRBJLV2'], listing_values=['PINC:BYDDF', 'PINC:BYDDY', 'XBKK:BYDCOM01', 'XBKK:BYDCOM80', 'XETR:BY6A', 'XFRA:BY6', 'XFRA:BY6A', 'XHKG:1211', 'XSEC:002594', 'XSES:HYDD', 'XSHE:002594']), Company(id='335CF4', name='SpaceX', volume=1027, description='Space Exploration Technologies Corp. (known as: SpaceX) operates as a space transportation company that designs, manufactures, and launches rockets and spacecraft. The company was founded in June, 2002.', entity_type='COMP', company_type='Private', country='United States', sector='Industrials', industry_group='Aerospace & Defense', industry='Aerospace', ticker=None, webpage='http://www.spacex.com', isin_values=None, cusip_values=None, sedol_values=None, listing_values=None), Company(id='940A72', name='CNBC LLC', volume=579, description='CNBC LLC is an American pay television business news channel that is owned by NBCUniversal Inc. The company was founded on the 17th of April 1989 as a wholly owned subsidiary.', entity_type='COMP', company_type='Private', country='United States', sector='Consumer Services', industry_group='Broadcasting', industry='Broadcasting', ticker=None, webpage='http://www.cnbc.com', isin_values=None, cusip_values=None, sedol_values=None, listing_values=None), Company(id='048590', name='Activision Blizzard Inc.', volume=447, description='Activision Blizzard Inc. (formerly Activision Inc.) is an independent interactive entertainment publishing company. It develops and publishes some of the most successful entertainment franchises. It was founded in 1979 as Activision Inc. On July 10th, 2008, Vivendi Games Inc. acquired a 52% stake in the company as a result of the merger between Activision Inc. and Vivendi Games Inc. On October 13th, 2013, Activision Blizzard Inc. completed the purchase of shares from owner Vivendi Games Inc., becoming an independent company as a majority of the shares became owned by the public. On October 13, 2023, it was acquired by Microsoft Corp. and delisted on October 16, 2023.', entity_type='COMP', company_type='Private', country='United States', sector='Consumer Goods', industry_group='Leisure Goods', industry='Toys', ticker=None, webpage='http://www.activisionblizzard.com', isin_values=None, cusip_values=None, sedol_values=None, listing_values=None), Company(id='ABB7EE', name='Xbox Game Studios Co.', volume=433, description='Xbox Game Studios Co., previously known as Microsoft Studios, is a division of Microsoft based in Redmond, Washington. It was established in March 2000.', entity_type='COMP', company_type='Private', country='United States', sector='Technology', industry_group='Software', industry='Software', ticker=None, webpage='https://www.xbox.com/en-US/xbox-game-studios', isin_values=None, cusip_values=None, sedol_values=None, listing_values=None), Company(id='134689', name='Elektros Inc.', volume=287, description='Elektros Inc. (formerly China Xuefeng Environmental Engineering Inc) is a development-stage company. The Company was founded in December 2007 as NYC Moda Inc. On May 28, 2021 Elektros Inc. effectuated a holding company reorganization with China Xuefeng Environmental Engineering Inc. and changed its name to Elektros Inc. on June 07, 2021.', entity_type='COMP', company_type='Public', country='United States', sector='Industrials', industry_group='Support Services', industry='Business Support Services', ticker='ELEK', webpage=None, isin_values=['US2861761029'], cusip_values=['286176102'], sedol_values=['BMZ1NN5'], listing_values=['PINX:ELEK']), Company(id='97EB87', name='Zacks Investment Research Inc.', volume=254, description='Zacks Investment Research Inc., founded in 1978, is an investment research firm focusing on stock research, analysis and recommendations.', entity_type='COMP', company_type='Private', country='United States', sector='Financials', industry_group='Other Diversified Financial Services', industry='Other Diversified Financial Services', ticker=None, webpage='http://www.zacks.com', isin_values=None, cusip_values=None, sedol_values=None, listing_values=None)])
('concepts', [Concept(id='C4F920', name='Stock', volume=33460, description='Stock is a security that represents the ownership of a fraction of a corporation.', entity_type='FINC', entity_type_name='Financial', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='38918B', name='Artificial Intelligence', volume=27359, description='Artificial Intelligence refers to the simulation of human intelligence in machines that are programmed to think like humans and mimic their actions.', entity_type='TECH', entity_type_name='Technology', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='FE1757', name='U.S. Dollar', volume=26023, description='The U.S. Dollar is the official currency of the United States of America. It is also the currency of Bonaire, Saint Eustatius and Saba, Marshall Islands, Palau, Puerto Rico, Panama, British Virgin Islands, East Timor, Guam, Northern Mariana Islands, U.S. Virgin Islands, Micronesia, British Indian Ocean Territory, Zimbabwe, Ecuador, Turks and Caicos Islands, United States Minor Outlying Islands, American Samoa, El Salvador. It was introduced in 1792.', entity_type='CURR', entity_type_name='Currency', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='913660', name='Customer', volume=12874, description="Customer is an individual or business that purchases another company's goods or services.", entity_type='BUSI', entity_type_name='Business', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='E735C9', name='Business', volume=10444, description='Business refers to the activity of making, buying, and selling goods or services for profit.', entity_type='BUSI', entity_type_name='Business', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='CC71F7', name='Data', volume=8407, description='Data are characteristics or information, usually numerical, that are collected through observation.', entity_type='TECH', entity_type_name='Technology', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='9DB5BD', name='Tariff', volume=6605, description='Tariff is a tax imposed by one country on the goods and services imported from another country.', entity_type='ECON', entity_type_name='Economics', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='168FE8', name='Earnings', volume=6018, description="Earnings refer to a company's profits in a given quarter or fiscal year.", entity_type='FINC', entity_type_name='Financial', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='F26C2F', name='Technology', volume=5954, description='Technology is the application of scientific knowledge for practical purposes, especially in industry.', entity_type='TECH', entity_type_name='Technology', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='E1B51E', name='Ability', volume=5888, description='Ability is the possession of the means or skill to do something.', entity_type='SOCI', entity_type_name='Society', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='5E647F', name='Revenue', volume=5722, description='Revenue is the income generated from normal business operations and includes discounts and deductions for returned merchandise.', entity_type='FINC', entity_type_name='Financial', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='CDE48B', name='Protest', volume=5257, description='Protest is a public expression of objection, disapproval, or dissent towards an idea or action, typically a political one.', entity_type='SOCI', entity_type_name='Society', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='8F1E07', name='Brand', volume=5218, description='Brand refers to a business and marketing concept that helps people identify a particular company, product, or individual.', entity_type='BUSI', entity_type_name='Business', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='E3E549', name='Collaboration', volume=4845, description='Collaboration is the process of two or more people, entities or organizations working together to complete a task or achieve a goal.', entity_type='SOCI', entity_type_name='Society', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='89FCE6', name='Trade', volume=4810, description='Trade is a basic economic concept involving the buying and selling of goods and services, with compensation paid by a buyer to a seller, or the exchange of goods or services between parties.', entity_type='ECON', entity_type_name='Economics', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='9CC31E', name='Demand', volume=4664, description="Demand is an economic principle referring to a consumer's desire to purchase goods and services and willingness to pay a price for a specific good or service.", entity_type='ECON', entity_type_name='Economics', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='5442E4', name='Industry', volume=4660, description='Industry is a group of companies that are related based on their primary business activities.', entity_type='BUSI', entity_type_name='Business', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='103AC2', name='Competition', volume=4577, description="Competition is a rivalry where two or more parties strive for a common goal that cannot be shared: where one's gain is the other's loss.", entity_type='SOCI', entity_type_name='Society', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='015557', name='Investment', volume=4197, description='Investment refers to an asset or item that is purchased with the hope that it will generate income or appreciate in value at some point in the future.', entity_type='FINC', entity_type_name='Financial', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='5C3ECD', name='Technology', volume=4174, description='The Technology Industry consists of companies that develop or distribute technologically based goods and services. Examples include manufacturers of creation of software, computers or products and services relating to information technology.', entity_type='SECT', entity_type_name='Sector', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='166EC5', name='Politics', volume=3973, description='Politics are the activities of governments concerning the political relations between states.', entity_type='PLTC', entity_type_name='Politics', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='23E2A4', name='Cost', volume=3486, description='Cost is an amount that has to be paid or spent to buy or obtain something.', entity_type='FINC', entity_type_name='Financial', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='4A07D9', name='Big Tech', volume=3486, description='Big Tech is a large, influential, and successful company that operates primarily in the technology sector.', entity_type='BUSI', entity_type_name='Business', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='30371F', name='Partnership', volume=3227, description='Partnership is a formal arrangement by two or more parties to manage and operate a business and share its profits.', entity_type='BUSI', entity_type_name='Business', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='277B39', name='Price', volume=3026, description='A Price is the monetary value of a good, service or resource established during a transaction.', entity_type='ECON', entity_type_name='Economics', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='5AF7E2', name='Earnings Call', volume=2866, description='Earnings Call is a conference call between the management of a public company, analysts, investors, and the media to discuss the company’s financial results during a given reporting period, such as a quarter or a fiscal year.', entity_type='FINC', entity_type_name='Financial', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='9B8E99', name='Fiscal First Quarter', volume=2683, description='Fiscal First Quarter refers to the first of the four three-month periods that make up a fiscal year.', entity_type='FINC', entity_type_name='Financial', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='FB0726', name='Chinese', volume=2646, description='The status of belonging to China.', entity_type='NATL', entity_type_name='Nationalities', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='A94769', name='Billionaire', volume=2613, description='A Billionaire is a person with a net worth of at least one billion units of a given currency, usually of a major currency such as the United States dollar, the euro, or the British pound', entity_type='FINC', entity_type_name='Financial', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='56E3D3', name='European', volume=2587, description='Relating to or characteristic of Europe or its inhabitants.', entity_type='NATL', entity_type_name='Nationalities', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='253C3A', name='Profit', volume=2546, description='Profit describes the financial benefit realized when revenue generated from a business activity exceeds the expenses, costs, and taxes involved in sustaining the activity in question.', entity_type='FINC', entity_type_name='Financial', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='82D908', name='Layoff', volume=2008, description="Layoff describes the act of an employer suspending or terminating a worker, either temporarily or permanently, for reasons other than an employee's actual performance.", entity_type='BUSI', entity_type_name='Business', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='36EF49', name='Wall Street', volume=2008, description='Wall Street is a street located in the lower Manhattan section of New York City and is the home of the New York Stock Exchange or NYSE.', entity_type='FINC', entity_type_name='Financial', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='1DF2FC', name='Price Target', volume=1978, description="Price Target is an analyst's projection of a security's future price, one at which an analyst believes a stock is fairly valued.", entity_type='FINC', entity_type_name='Financial', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='B0F242', name='Finance', volume=1760, description='Finance refers to any term or concept that describes activities associated with banking, leverage or debt, credit, capital markets, funds, and investments.', entity_type='FINC', entity_type_name='Financial', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='D6119F', name='Event', volume=1678, description='An event is something that happens or is regarded as happening; an occurrence, especially one of some importance.', entity_type='EVNT', entity_type_name='Event', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='56B19A', name='Workforce', volume=1649, description='Workforce is the people engaged in or available for work, either in a country or area or in a particular firm or industry.', entity_type='BUSI', entity_type_name='Business', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='5828F2', name='Conference', volume=1618, description='A Conference is a large official meeting, usually lasting for a few days, at which people with the same work or interests come together to discuss their views.', entity_type='EVNT', entity_type_name='Event', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='393B6E', name='Experience', volume=1452, description='Experience is the knowledge or skill from doing, seeing, or feeling things.', entity_type='SOCI', entity_type_name='Society', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='7E7529', name='Production', volume=1388, description='Production is a process of combining various material inputs and immaterial inputs in order to make something for consumption.', entity_type='ECON', entity_type_name='Economics', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='2606FF', name='Email', volume=1291, description='Email is a method of exchanging messages instantly from one system to another with the help of the internet.', entity_type='TECH', entity_type_name='Technology', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='E7C37B', name='Automobiles', volume=1257, description='The Automobiles Sector consists of companies engaged in the manufacturing of non-commercial vehicles. Examples include motorcycles and passenger vehicles, including cars, sport utility vehicles (SUVs) and light trucks. Excludes makers of heavy trucks, which are classified under Commercial Vehicles and Trucks, and makers or recreational vehicles (RVs and ATVs), which are classified under Recreational Products.', entity_type='SECT', entity_type_name='Sector', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='2B712D', name='Fiscal Year', volume=1248, description='Fiscal Year (FY) is a one-year period that companies and governments use for financial reporting and budgeting.', entity_type='FINC', entity_type_name='Financial', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='680248', name='Stock Price', volume=1065, description='Stock Price is a current price that a share of stock is trading for on the market.', entity_type='FINC', entity_type_name='Financial', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='38803F', name='Generative Artificial Intelligence', volume=921, description='Generative Artificial Intelligence is a type of artificial intelligence that involves unsupervised and semi-supervised algorithms that enable computers to create new content using previously created content, such as text, audio, video, images, and code.', entity_type='TECH', entity_type_name='Technology', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='8B9CCA', name='Leadership and Strategic Competencies', volume=904, description='Leadership and Strategic Competencies refer to the ability of an individual or a group of individuals to influence and guide followers or other members of an organization.', entity_type='SOCI', entity_type_name='Society', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='808756', name='Automation', volume=894, description='Automation is the use or introduction of automatic equipment in a manufacturing or other process or facility.', entity_type='TECH', entity_type_name='Technology', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='642F5F', name='Productivity', volume=834, description='Productivity describes various measures of the efficiency of production.', entity_type='BUSI', entity_type_name='Business', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='9A889D', name='Startup', volume=782, description='Startup refers to a company in the first stages of operations.', entity_type='BUSI', entity_type_name='Business', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='043BCB', name='Running', volume=760, description='Running is both a competition and a type of training for sports that have running or endurance components.', entity_type='SPOR', entity_type_name='Sports', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='BD7915', name='Expertise', volume=634, description='Expertise is the expert skill or knowledge in a particular field.', entity_type='SOCI', entity_type_name='Society', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='443499', name='Workflow', volume=605, description='Workflow describes the steps in a business work process, through which a piece of work passes from initiation to completion.', entity_type='BUSI', entity_type_name='Business', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='B1BBFB', name='Fiscal Third Quarter', volume=603, description='Fiscal Third Quarter refers to the third of the four three-month periods that make up a fiscal year.', entity_type='FINC', entity_type_name='Financial', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='5828FC', name='Community', volume=581, description='Community is a social unit with commonality such as norms, religion, values, customs, or identity.', entity_type='SOCI', entity_type_name='Society', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='C3862D', name='Contractual Agreements', volume=580, description='Contractual Agreements are legal agreements between a buyer and seller of goods or services.', entity_type='BUSI', entity_type_name='Business', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='E3946E', name='Market Capitalization', volume=567, description='Market Capitalization is the aggregate market value of a company represented in dollar amount.', entity_type='BUSI', entity_type_name='Business', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='27766D', name='Israeli', volume=565, description='The status of belonging to Israel.', entity_type='NATL', entity_type_name='Nationalities', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='A1FEA6', name='American', volume=507, description='The status of belonging to the United States of America.', entity_type='NATL', entity_type_name='Nationalities', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='A76B67', name='Form 10-Q', volume=432, description="Form 10-Q is a comprehensive report of a company's performance that must be submitted quarterly by all public companies to the Securities and Exchange Commission (SEC).", entity_type='BUSI', entity_type_name='Business', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='41CBAE', name='Carbon Sequestration', volume=380, description='Carbon Sequestration is the process of capturing and storing atmospheric carbon dioxide. It is one method of reducing the amount of carbon dioxide in the atmosphere with the goal of reducing global climate change.', entity_type='SUST', entity_type_name='Sustainability', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='F4F4E2', name='Futures', volume=359, description='A Futures contract (Futures) is a standardized legal agreement to buy or sell something at a predetermined price at a specified time in the future.', entity_type='SCTY', entity_type_name='Security Type', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='C1A895', name='Arson', volume=326, description='Arson is the crime of willful and malicious burning or charring of property.', entity_type='LAWS', entity_type_name='Legal', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='6A7BC6', name='Lawsuit', volume=283, description='Lawsuit is a civil legal action by one person or entity (the plaintiff) against another person or entity (the defendant), to be decided in a court.', entity_type='LAWS', entity_type_name='Legal', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='25EB30', name='Vandalism', volume=283, description='Vandalism is a crime of willfully destroying, altering, or defacing property belonging to another.', entity_type='LAWS', entity_type_name='Legal', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None), Concept(id='751AFD', name='Malware', volume=264, description='Malware is any software intentionally designed to cause damage to a computer, server, client, or computer network.', entity_type='TECH', entity_type_name='Technology', concept_level_2=None, concept_level_3=None, concept_level_4=None, concept_level_5=None)])
('languages', [Language(id='EN', name='English', volume=65416, description=None, query_type='language')])
('organizations', [Organization(id='1BC945', name='Government of the United States', volume=4809, description="The Government of the United States is the national government of the United States, a republic in North America, composed of 50 states, one district, Washington, D.C. (the nation's capital), and several territories. It was created in 1789.", entity_type='ORGA', organization_type='Federal Republic', country='United States'), Organization(id='CCCAF6', name='U.S. DOGE Service Temporary Organization', volume=2754, description='The U.S. DOGE Service Temporary Organization, which reports to the United States DOGE Service, was established to modernize federal technology and software to maximize governmental efficiency and productivity. It was created on January 20, 2025.', entity_type='ORGA', organization_type='Governmental Committee', country='United States'), Organization(id='E5FA3A', name='European Union', volume=2579, description='The European Union (EU) is a politico-economic union of member states that are located in Europe.\r\nThe EU operates through a system of supranational institutions and intergovernmental-negotiated decisions by the member states.\r\nThe Maastricht Treaty established the European Union under its current name in 1993 and introduced European citizenship. \r\nThe European Union had its origins from the European Coal and Steel Community (ECSC) and the European Economic Community (EEC), formed by the Inner Six countries (Belgium, France, Italy, Luxembourg, the Netherlands and West Germany) in 1951 and 1958.', entity_type='ORGA', organization_type='Economic Union', country=None), Organization(id='79FCE1', name='European Automobile Manufacturers Association', volume=748, description="The European Automobile Manufacturers' Association (ACEA) represents the 15 Europe-based car, van, truck and bus makers: BMW Group, Daimler, DAF, Fiat, Ford of Europe, General Motors Europe, Hyundai Motor Europe, Iveco, Jaguar Land Rover, PSA Peugeot Citroën, Renault, Toyota Motor Europe, Volkswagen Group, Volvo Cars, Volvo Group. It was established in February, 1991.", entity_type='ORGA', organization_type='Association', country=None), Organization(id='96046F', name='Israel Defense Forces', volume=548, description='The Israel Defense Forces is the military forces of the State of Israel. It is responsible for the defense and security of Israel, as well as maintaining peace and stability within its borders. The IDF comprises the Ground Forces, Air Force, and Navy. Founded in 1948.', entity_type='ORGA', organization_type='Army', country='Israel'), Organization(id='E49C60', name='Federal Trade Commission of the United States', volume=495, description='Federal Trade Commission of the United States (FTC) is an independent agency of the United States government, established in 1914 by the Federal Trade Commission Act. Its principal mission is the promotion of consumer protection and the elimination and prevention of anticompetitive business practices, such as coercive monopoly.', entity_type='ORGA', organization_type='Governmental Agency', country='United States'), OrganizationType(id='983634', name='Stock Exchange', volume=266, description='A Stock Exchange is an organized and regulated financial market where securities (bonds, notes, shares) are bought and sold at prices governed by the forces of demand and supply.', entity_type='ORGT'), OrganizationType(id='DB0287', name='Exchange Traded Fund', volume=265, description='An Exchange Traded Fund is a type of fund that is traded on the public exchanges like stocks.', entity_type='ORGT')])
('places', [Place(id='3D4567', name='United States of America', volume=17569, description='The United States of America is a country located in North America.', entity_type='PLCE', place_type='Country', country='United States', region=None), Place(id='9DBA1F', name='European Union Area', volume=8287, description='The European Union Area is the geographical region covering the economic and political union delineated by the European Union.', entity_type='PLCE', place_type='Country', country=None, region=None), Place(id='13FF12', name='China', volume=6967, description="The People's Republic of China is a country located in East Asia.", entity_type='PLCE', place_type='Country', country='China', region=None), Facility(id='FA1880', name='Data Center', volume=2619, description='Data Center is a facility used to house computer systems and associated components, such as telecommunications and storage systems.', entity_type='FCTY', country=None, region=None), Place(id='BEAA45', name='Austin', volume=1185, description='Austin is a city located in the United States, in the state of Texas.', entity_type='PLCE', place_type='City', country='United States', region='State of Texas'), Place(id='609489', name='United Kingdom', volume=978, description='The United Kingdom, made up of England, Scotland, Wales and Northern Ireland, is an island nation in northwestern Europe', entity_type='PLCE', place_type='Country', country='United Kingdom', region=None), Place(id='29AE6B', name='Washington D.C., WA, US', volume=710, description='Washington D.C. is the capital city of the United States, located on the East Coast.', entity_type='PLCE', place_type='City', country='United States', region='District of Columbia'), Facility(id='8A982E', name='Factory', volume=594, description='A factory is a building or group of buildings with facilities for the manufacture of goods.', entity_type='FCTY', country=None, region=None), Place(id='918F78', name='Seattle', volume=507, description='Seattle is a city located in the United States, in the state of Washington.', entity_type='PLCE', place_type='City', country='United States', region='State of Washington'), Place(id='FCF6C7', name='New York City', volume=484, description='New York City is a city located in the United States, in the state of New York.', entity_type='PLCE', place_type='City', country='United States', region='State of New York'), Place(id='C4EEAD', name='India', volume=397, description='The Republic of India is a country located in South Asia.', entity_type='PLCE', place_type='Country', country='India', region=None), Place(id='0D9EE5', name='Gaza Strip', volume=384, description='The Gaza Strip, or simply Gaza, is a small, densely populated territory located on the eastern coast of the Mediterranean Sea. It is the smaller of the two Palestinian territories.', entity_type='PLCE', place_type='Region', country='Palestinian Territory', region='Gaza Strip'), Place(id='C1BA53', name='State of Texas', volume=290, description='Texas is a state located in the United States, in the southern region.', entity_type='PLCE', place_type='Region', country='United States', region='State of Texas'), Place(id='AFD601', name='State of California', volume=273, description='California is a state located in the United States, on the West Coast.', entity_type='PLCE', place_type='Region', country='United States', region='State of California'), Place(id='DBE5C1', name='Palestinian Territory', volume=251, description=None, entity_type='PLCE', place_type='Country', country='Palestinian Territory', region=None)])
('products', [Product(id='C7BCE3', name='Tesla Automobile', volume=30574, description='Tesla Automobile is battery electric vehicle (BEV) car produced by the electric car firm Tesla Motors in 2008.', entity_type='PROD', product_type='Electric Cars', product_owner='Tesla Inc.'), ProductType(id='E4AFAD', name='Automotive Vehicles', volume=18174, description='Automotive Vehicles refer to a broad category of motorized vehicles designed for transportation on roads.', entity_type='PRDT'), ProductType(id='2E2992', name='Electric Cars', volume=14852, description='Electric Cars refer to vehicles that are powered entirely or primarily by electric motors, using energy stored in rechargeable batteries instead of conventional internal combustion engines that run on gasoline or diesel.', entity_type='PRDT'), Product(id='B2AF23', name='Microsoft Azure', volume=9752, description='Microsoft Azure is a cloud-computing developed by Microsoft Corp. It was first announced on February 1, 2010.', entity_type='PROD', product_type='Cloud Computing Services', product_owner='Microsoft Corp.'), Product(id='1629F2', name='Tesla Cybertruck', volume=4093, description='Tesla Cybertruck is an Electric Vehicle developed by Tesla Inc. It was first announced as a concept on October 14 2019, and was officially announced on November 6, 2019.', entity_type='PROD', product_type='Electric Truck', product_owner='Tesla Inc.'), Product(id='39E5EB', name='Google Search', volume=2929, description='Google Search is a web search engine developed by Alphabet Inc. It was launched on the 15th of September 1997.', entity_type='PROD', product_type='Search Engines Services', product_owner='Alphabet Inc.'), Product(id='DF5199', name='Tesla Model Y', volume=2459, description='Tesla Model Y is an electric SUV designed and manufactured by Tesla Inc. It was announced on March 14, 2019.', entity_type='PROD', product_type='Electric Sport Utility Vehicle', product_owner='Tesla Inc.'), Product(id='C2574B', name='Microsoft Windows', volume=2273, description='Microsoft Windows is a a graphical operating system shell for MS-DOS in response to the growing interest in graphical user interfaces (GUIs). It was introduced by Microsoft Corp. on November 20, 1985.', entity_type='PROD', product_type='Operating System (OS)', product_owner='Microsoft Corp.'), Product(id='83C493', name='Microsoft Copilot', volume=2033, description='Microsoft Copilot (formerly Microsoft Bing AI) is a search engine-integrated AI chatbot developed by Microsoft Corp. It was announced on February 08, 2023.', entity_type='PROD', product_type='Chatbot', product_owner='Microsoft Corp.'), Product(id='A8903F', name='Microsoft Teams', volume=1965, description='Microsoft Teams is an instant chat app developed by Microsoft Corp. for its Office 365 suite. Team Rooms is a part of Microsoft Teams. It was officially unveiled on November 2, 2016.', entity_type='PROD', product_type='Instant Messaging Services', product_owner='Microsoft Corp.'), ProductType(id='A4716E', name='Cloud Computing Services', volume=1882, description='Cloud Computing Services refer to services that provide scalable computing resources, such as storage, processing power, and networking, over the Internet, enabling businesses to access and manage data and applications remotely without the need for physical infrastructure.', entity_type='PRDT'), Product(id='195E55', name='Office 365', volume=1716, description='Office 365 is a group of software and services subscriptions, which together provide productivity software and related services to subscribers. The product was created and developed by Microsoft Corp. It was officially announced on June 28, 2011.', entity_type='PROD', product_type='Productivity Software', product_owner='Microsoft Corp.'), ProductType(id='11C01D', name='Application Software', volume=1389, description='Application Software is a computer program designed to perform a group of coordinated functions, tasks, or activities for the benefit of the user.', entity_type='PRDT'), ProductType(id='7A94A9', name='Artificial Intelligence Platform', volume=1255, description='An Artificial Intelligence Platform is the broader concept of machines that are able to carry out tasks through the simulation of human intelligence processes like learning, reasoning and self-correction.', entity_type='PRDT'), ProductType(id='ADD83D', name='Battery', volume=736, description='A Battery is a device or container consisting of one or more cells, in which chemical energy is converted into electricity and used as a source of power.', entity_type='PRDT'), ProductType(id='225840', name='Cloud Services', volume=515, description='Cloud Services refer to a broad range of computing resources and solutions that are delivered over the internet.', entity_type='PRDT'), Product(id='45DF80', name='Xbox', volume=400, description='The Xbox is a series of non portable video game consoles developed by Microsoft Corp. The first product from this series was announced on November 15, 2001.', entity_type='PROD', product_type='Non Portable Video Game Console', product_owner='Microsoft Corp.'), Product(id='B45194', name='Microsoft 365 Copilot', volume=273, description='Microsoft 365 Copilot is an Artificial Intelligence Platform developed by Microsoft Corp. It was announced on March 16, 2023.', entity_type='PROD', product_type='Artificial Intelligence Platform', product_owner='Microsoft Corp.'), Product(id='3F2C19', name='Tesla Full Self-Driving', volume=268, description='The Tesla Full Self-Driving is an autonomous driving application software developed by Tesla Inc. It was first introduced on October 22, 2015.', entity_type='PROD', product_type='Application Software', product_owner='Tesla Inc.')])
('sources', [Source(id='E5AA62', name='Yahoo! Finance', volume=17948, description='Yahoo! Finance is an Internet web site sponsored by Yahoo! that provides financial news and information.', entity_type='SRCE', publication_type='News', language='English', country='United States', source_rank='2', provider_id='MRVR', url='http://finance.yahoo.com'), Source(id='5A5702', name='Benzinga', volume=11012, description="Benzinga is a dynamic and innovative financial media outlet that empowers investors with high-quality, unique content that is coveted by Wall Street's top traders. This source includes content received in real-time directly from Benzinga", entity_type='SRCE', publication_type='News', language='English', country='United States', source_rank='1', provider_id='BZG', url='http://www.benzinga.com/'), Source(id='648085', name='AOL.com', volume=7365, description='AOL.com delivers breaking news and the latest headlines on business, entertainment, politics, world news, tech, sports, and videos.', entity_type='SRCE', publication_type='News', language='English', country='United States', source_rank='2', provider_id='MRVR', url='http://www.aol.com'), Source(id='D904DE', name='Associated Press', volume=3341, description='The Associated Press is an American multinational non-profit news agency headquartered in New York City.', entity_type='SRCE', publication_type='News', language='English', country='United States', source_rank='1', provider_id='MRVR', url='http://www.ap.org'), Source(id='7DFD4A', name='Nasdaq', volume=3043, description='Nasdaq Stock Market website features stock quotes, analysis, financials, company news, market information as well as investing tools and guides.', entity_type='SRCE', publication_type='News', language='English', country='United States', source_rank='2', provider_id='MRVR', url='http://www.nasdaq.com/'), Source(id='C307F2', name='The Economic Times', volume=2892, description='The Economic Times is an English-language Indian business-focused daily newspaper published by The Times Group.', entity_type='SRCE', publication_type='News', language='English', country='India', source_rank='2', provider_id='MRVR', url='http://www.economictimes.indiatimes.com'), Source(id='22AC8B', name='Forbes.com via Web', volume=2438, description='Forbes is an American business magazine owned by Forbes, Inc. Published biweekly, it features original articles on finance, industry, investing, and marketing topics. Forbes also reports on related subjects such as technology, communications, science, and law.', entity_type='SRCE', publication_type='News', language='English', country='United States', source_rank='1', provider_id='MRVR', url='http://www.forbes.com'), Source(id='E50739', name='Edgar SEC Filings', volume=1936, description='SEC filings sourced directly from the Edgar online.', entity_type='SRCE', publication_type='News', language='English', country='United States', source_rank='1', provider_id='EDGAR', url='https://www.sec.gov/edgar'), Source(id='D4B903', name='Factset Transcripts', volume=1794, description='Factset Transcripts is a source that provides transcript content collected from Factset.', entity_type='SRCE', publication_type='News', language='English', country='United States', source_rank='1', provider_id='FSTR', url='https://www.factset.com'), Source(id='DA0F7F', name='Quartr Transcripts', volume=1644, description='Quartr Transcripts is an offering that provides transcripts of earnings calls, shareholder meetings, and other financial events. It is provided by Quartr, a software company serving the world of finance, focused on qualitative public market research.', entity_type='SRCE', publication_type='Transcript', language='English', country='Sweden', source_rank='1', provider_id='QRTR', url='https://quartr.com'), Source(id='80FC03', name='The Times Of India', volume=1580, description='The Times of India (TOI) is an Indian English-language daily newspaper. According to Audit Bureau of Circulations, it has the largest circulation among all English-language newspapers in the world, across all formats (broadsheet, tabloid, compact, Berliner and online).', entity_type='SRCE', publication_type='News', language='English', country='India', source_rank='2', provider_id='MRVR', url='http://www.timesofindia.indiatimes.com'), Source(id='9D69F1', name='MT Newswires', volume=1466, description='MT Newswires offers real time corporate and financial news to both retail and institutional investors.', entity_type='SRCE', publication_type='News', language='English', country='United States', source_rank='1', provider_id='MT', url='http://mtnewswires.com'), Source(id='4A513E', name='Cision PR Newswire', volume=1450, description='Full text news stories from the PR Newswire delivered by LexisNexis content provider.', entity_type='SRCE', publication_type='News', language='English', country='United States', source_rank='1', provider_id='MRVR', url='http://www.prnewswire.com/news-releases/'), Source(id='29B277', name='Miami Herald (MH)', volume=1290, description='Full text news stories from the Miami Herald delivered by LexisNexis content provider.', entity_type='SRCE', publication_type='News', language='English', country='United States', source_rank='1', provider_id='MRVR', url='http://www.miamiherald.com/'), Source(id='2435A4', name='CNN', volume=1187, description='Cable News Network (CNN) is an American basic cable, satellite television and online news channel that provides 24-hour television news coverage.', entity_type='SRCE', publication_type='News', language='English', country='United States', source_rank='1', provider_id='MRVR', url='http://cnn.com'), Source(id='7018D1', name='Charlotte Observer', volume=1153, description='The Charlotte Observer, serving Charlotte, North Carolina and its metro area, is the largest newspaper, in terms of circulation, in North Carolina and South Carolina.', entity_type='SRCE', publication_type='News', language='English', country='United States', source_rank='2', provider_id='MRVR', url='http://www.charlotteobserver.com'), Source(id='FAECE8', name='Investing.com via Web', volume=1072, description='Investing.com is a global financial portal that provides news, analysis, streaming quotes and charts, technical data and financial tools about the global financial markets.', entity_type='SRCE', publication_type='News', language='English', country='Israel', source_rank='3', provider_id='MRVR', url='https://www.investing.com'), Source(id='1FE370', name='Business Wire (BW)', volume=981, description='Business Wire is a global leader in press release distribution and regulatory disclosure.', entity_type='SRCE', publication_type='News', language='English', country='United States', source_rank='1', provider_id='MRVR', url='https://www.businesswire.com/portal/site/home/'), Source(id='29062E', name='Yahoo! News', volume=966, description='Yahoo News is an Internet-based news aggregator by Yahoo. The site also includes premium content licensed by Yahoo.', entity_type='SRCE', publication_type='News', language='English', country='United States', source_rank='3', provider_id='MRVR', url='http://news.yahoo.com/'), Source(id='E54C73', name='ABC News', volume=858, description='ABC News is the news gathering and broadcasting division of the American Broadcasting Company, a subsidiary of The Walt Disney Company.', entity_type='SRCE', publication_type='General', language='English', country='United States', source_rank='1', provider_id='MRVR', url='http://abcnews.go.com')])
('topics', [Topic(id='business,revenues,revenue,down,', name='Revenue Down', volume=6203, description='Sales figures fall', topic='business', topic_group='revenues', entity_type='TOPC'), Topic(id='business,stock-prices,stock-price,loss,', name='Stock Loss', volume=5648, description='Share price falls', topic='business', topic_group='stock-prices', entity_type='TOPC'), Topic(id='business,partnerships,partnership,,', name='Partnership', volume=5408, description='An agreement between two or more parties to share responsibility for a business', topic='business', topic_group='partnerships', entity_type='TOPC'), Topic(id='business,stock-prices,stock-price,gain,', name='Stock Gain', volume=5151, description='Share price rises', topic='business', topic_group='stock-prices', entity_type='TOPC'), Topic(id='business,products-services,product-release,,', name='Product Release', volume=3713, description='A new product or service is launched', topic='business', topic_group='products-services', entity_type='TOPC'), Topic(id='business,investor-relations,earnings-call,,', name='Earnings Call', volume=2962, description="A conference call held to discuss a company's financial results", topic='business', topic_group='investor-relations', entity_type='TOPC'), Topic(id='business,earnings,earnings,,', name='Earnings', volume=2323, description='Net income of a company', topic='business', topic_group='earnings', entity_type='TOPC'), Topic(id='business,labor-issues,layoffs,,', name='Layoffs', volume=2109, description='Permanent release of an employee from their job', topic='business', topic_group='labor-issues', entity_type='TOPC'), Topic(id='business,revenues,revenue,up,', name='Revenue Up', volume=1245, description='Sales figures rise', topic='business', topic_group='revenues', entity_type='TOPC'), Topic(id='business,products-services,business-contract,,', name='Business Contract', volume=1234, description='A company signs an agreement with another company', topic='business', topic_group='products-services', entity_type='TOPC'), Topic(id='society,legal,legal-issues,,', name='Legal Issues', volume=1085, description='A dispute between two or more parties that is brought to a court of law', topic='society', topic_group='legal', entity_type='TOPC'), Topic(id='business,earnings,earnings,down,', name='Earnings Down', volume=1052, description='Earnings results decrease', topic='business', topic_group='earnings', entity_type='TOPC'), Topic(id='business,acquisitions-mergers,acquisition,,', name='Acquisition', volume=1029, description="A company purchases most or all of another company's shares to gain control over it", topic='business', topic_group='acquisitions-mergers', entity_type='TOPC'), Topic(id='business,products-services,product-enhancement,,', name='Product Enhancement', volume=1005, description='An upgrade to an existing product or service', topic='business', topic_group='products-services', entity_type='TOPC'), Topic(id='business,products-services,product-recall,,', name='Product Recall', volume=967, description='A defective or unsafe product is retrieved from the market', topic='business', topic_group='products-services', entity_type='TOPC'), Topic(id='business,regulatory,regulatory-investigation,,', name='Regulatory Investigation', volume=871, description='An investigation conducted by a regulator or governmental authority', topic='business', topic_group='regulatory', entity_type='TOPC'), Topic(id='society,civil-unrest,protest,,', name='Protest', volume=732, description='A usually organized public demonstration of disapproval', topic='society', topic_group='civil-unrest', entity_type='TOPC'), Topic(id='business,revenues,revenue,,', name='Revenues', volume=679, description='Total sales of a company', topic='business', topic_group='revenues', entity_type='TOPC'), Topic(id='business,equity-actions,investment,,', name='Investment', volume=615, description='Commitment of resources with the goal of generating income or appreciation over time', topic='business', topic_group='equity-actions', entity_type='TOPC'), Topic(id='business,products-services,supply,,', name='Supply', volume=609, description='Total production levels', topic='business', topic_group='products-services', entity_type='TOPC'), Topic(id='business,labor-issues,executive-appointment,,', name='Executive Appointment', volume=570, description='A new executive is appointed', topic='business', topic_group='labor-issues', entity_type='TOPC'), Topic(id='business,products-services,product-discontinued,,', name='Product Discontinued', volume=540, description='A product or service is shut down', topic='business', topic_group='products-services', entity_type='TOPC'), Topic(id='business,stock-picks,stock-pick,buy,', name='Stock Pick Buy', volume=510, description='An analyst gives a positive recommendation on a stock', topic='business', topic_group='stock-picks', entity_type='TOPC'), Topic(id='business,products-services,product-pricing,raise,', name='Product Price Raise', volume=499, description='The price of a product or service is increased', topic='business', topic_group='products-services', entity_type='TOPC'), Topic(id='business,marketing,conference,,', name='Conference', volume=495, description='A conference or business event is held', topic='business', topic_group='marketing', entity_type='TOPC'), Topic(id='society,war-conflict,violence,attack,', name='Violent Attack', volume=491, description='A violent act intended to inflict harm', topic='society', topic_group='war-conflict', entity_type='TOPC'), Topic(id='business,analyst-ratings,analyst-ratings-change,neutral,', name='Analyst Ratings Change Neutral', volume=480, description='A stock rating is reiterated', topic='business', topic_group='analyst-ratings', entity_type='TOPC'), Topic(id='business,products-services,supply,decrease,', name='Supply Decrease', volume=467, description='Production levels fall', topic='business', topic_group='products-services', entity_type='TOPC'), Topic(id='business,regulatory,regulatory-filing,,', name='Regulatory Filing', volume=460, description='A company files a form with a regulatory body', topic='business', topic_group='regulatory', entity_type='TOPC'), Topic(id='business,stock-prices,stock-price,,', name='Stock Price', volume=456, description="Value of a company's shares", topic='business', topic_group='stock-prices', entity_type='TOPC'), Topic(id='business,earnings,earnings-expectations,above-expectations,', name='Earnings Above Expectations', volume=451, description='Earnings results are stronger than forecast', topic='business', topic_group='earnings', entity_type='TOPC'), Topic(id='business,price-targets,price-target,downgrade,', name='Price Target Downgrade', volume=442, description='An analyst lowers their estimate of the future price of a security', topic='business', topic_group='price-targets', entity_type='TOPC'), Topic(id='business,industrial-accidents,facility-accident,,', name='Facility Accident', volume=403, description='An accident takes place in a facility', topic='business', topic_group='industrial-accidents', entity_type='TOPC'), Topic(id='business,earnings,earnings,up,', name='Earnings Up', volume=384, description='Earnings results increase', topic='business', topic_group='earnings', entity_type='TOPC'), Topic(id='business,indexes,index-value,gain,', name='Index Gain', volume=377, description='The value of a stock index rises', topic='business', topic_group='indexes', entity_type='TOPC'), Topic(id='business,revenues,revenue-volume,,', name='Revenue Volume', volume=368, description='Number of units that are sold in a given time period', topic='business', topic_group='revenues', entity_type='TOPC'), Topic(id='business,indexes,index-value,loss,', name='Index Loss', volume=365, description='The value of a stock index falls', topic='business', topic_group='indexes', entity_type='TOPC'), Topic(id='business,products-services,government-contract,,', name='Government Contract', volume=359, description='A company secures a government contract for the provision of goods or services', topic='business', topic_group='products-services', entity_type='TOPC'), Topic(id='business,products-services,product-development,,', name='Product Development', volume=330, description='A new product is under development', topic='business', topic_group='products-services', entity_type='TOPC'), Topic(id='business,price-targets,price-target,upgrade,', name='Price Target Upgrade', volume=320, description='An analyst raises their estimate of the future price of a security', topic='business', topic_group='price-targets', entity_type='TOPC'), Topic(id='business,assets,facility,open,', name='Facility Open', volume=316, description='A new facility opens', topic='business', topic_group='assets', entity_type='TOPC'), Topic(id='business,earnings,earnings-expectations,below-expectations,', name='Earnings Below Expectations', volume=308, description='Earnings results are weaker than forecast', topic='business', topic_group='earnings', entity_type='TOPC'), Topic(id='business,acquisitions-mergers,stake,,', name='Stake', volume=282, description='A company buys a stake in another company', topic='business', topic_group='acquisitions-mergers', entity_type='TOPC'), Topic(id='business,products-services,product-outage,,', name='Product Outage', volume=259, description='An interruption in the provision of a product or service', topic='business', topic_group='products-services', entity_type='TOPC'), Topic(id='business,insider-trading,insider-sell,,', name='Insider Sell', volume=258, description='A director, officer, or executive sells corporate stock', topic='business', topic_group='insider-trading', entity_type='TOPC'), Topic(id='business,revenues,revenue,above-expectations,', name='Revenue Above Expectations', volume=248, description='Sales figures are stronger than forecast', topic='business', topic_group='revenues', entity_type='TOPC'), Topic(id='business,labor-issues,executive-search,,', name='Executive Search', volume=246, description='A company is looking for a new executive', topic='business', topic_group='labor-issues', entity_type='TOPC'), Topic(id='business,investor-relations,conference-call,,', name='Conference Call', volume=229, description='A conference call is held', topic='business', topic_group='investor-relations', entity_type='TOPC'), Topic(id='business,products-services,market-entry,,', name='Market Entry', volume=224, description='A company enters a new market or industry', topic='business', topic_group='products-services', entity_type='TOPC'), Topic(id='business,products-services,award,,', name='Award', volume=223, description='An award, prize, or recognition is given', topic='business', topic_group='products-services', entity_type='TOPC'), Topic(id='society,crime,vandalism,,', name='Vandalism', volume=222, description='Deliberate destruction of public or private property', topic='society', topic_group='crime', entity_type='TOPC'), Topic(id='business,revenues,revenue-volume,up,', name='Revenue Volume Up', volume=222, description='Sales volume rises', topic='business', topic_group='revenues', entity_type='TOPC'), Topic(id='business,products-services,market-share,loss,', name='Market Share Loss', volume=215, description='Market share shrinks', topic='business', topic_group='products-services', entity_type='TOPC'), Topic(id='society,legal,antitrust-investigation,,', name='Antitrust Investigation', volume=209, description='A probe into possible anticompetitive practices', topic='society', topic_group='legal', entity_type='TOPC'), Topic(id='business,revenues,revenue-volume,down,', name='Revenue Volume Down', volume=199, description='Sales volume falls', topic='business', topic_group='revenues', entity_type='TOPC'), Topic(id='business,labor-issues,executive-resignation,,', name='Executive Resignation', volume=196, description='An executive steps down from their post', topic='business', topic_group='labor-issues', entity_type='TOPC'), Topic(id='society,security,explosion,,', name='Explosion', volume=193, description='A sudden, violent burst of energy', topic='society', topic_group='security', entity_type='TOPC'), Topic(id='business,products-services,product-pricing,cut,', name='Product Price Cut', volume=188, description='The price of a product or service is reduced', topic='business', topic_group='products-services', entity_type='TOPC'), Topic(id='business,products-services,product-release,delayed,', name='Product Delayed', volume=187, description='The launch of a new product or service is postponed', topic='business', topic_group='products-services', entity_type='TOPC'), Topic(id='society,reputation,reputation,positive,', name='Reputation Positive', volume=181, description='A positive opinion or view on the entity', topic='society', topic_group='reputation', entity_type='TOPC'), Topic(id='society,crime,shooting,,', name='Shooting', volume=179, description='Shooting of a firearm with the intent to harm or kill', topic='society', topic_group='crime', entity_type='TOPC'), Topic(id='business,products-services,product-pricing,,', name='Product Price', volume=172, description='A new product or service is priced', topic='business', topic_group='products-services', entity_type='TOPC'), Topic(id='business,earnings,earnings,positive,', name='Earnings Positive', volume=170, description='Earnings results show a net profit', topic='business', topic_group='earnings', entity_type='TOPC'), Topic(id='business,investor-relations,investor-day,,', name='Investor Day', volume=163, description="A company's senior management meets with its main investors", topic='business', topic_group='investor-relations', entity_type='TOPC'), Topic(id='business,earnings,earnings,negative,', name='Earnings Negative', volume=162, description='Earnings results show a net loss', topic='business', topic_group='earnings', entity_type='TOPC'), Topic(id='economy,foreign-exchange,currency-rate,,', name='Currency Rate', volume=161, description='Rate at which one currency can be exchanged for another currency', topic='economy', topic_group='foreign-exchange', entity_type='TOPC'), Topic(id='business,investor-relations,shareholders-meeting,,', name='Shareholders Meeting', volume=160, description='A formal gathering of the shareholders of a company', topic='business', topic_group='investor-relations', entity_type='TOPC'), Topic(id='politics,elections,elections,results,', name='Election Results', volume=153, description='Voting results in an election', topic='politics', topic_group='elections', entity_type='TOPC'), Topic(id='business,labor-issues,board-member-appointment,,', name='Board Member Appointment', volume=145, description='A new member of the board is appointed', topic='business', topic_group='labor-issues', entity_type='TOPC'), Topic(id='business,products-services,supply,increase,', name='Supply Increase', volume=145, description='Production levels rise', topic='business', topic_group='products-services', entity_type='TOPC'), Topic(id='politics,elections,elections,,', name='Elections', volume=141, description='An organized vote to choose a person or group of people to hold an official position', topic='politics', topic_group='elections', entity_type='TOPC'), Topic(id='business,earnings,earnings-estimate,,', name='Earnings Estimate', volume=140, description="An analyst's forecast for a company's earnings", topic='business', topic_group='earnings', entity_type='TOPC'), Topic(id='society,legal,settlement,,', name='Settlement', volume=136, description='An official agreement intended to end a dispute', topic='society', topic_group='legal', entity_type='TOPC'), Topic(id='business,products-services,competition,,', name='Competition', volume=134, description='A product is involved in a competitive market or sector', topic='business', topic_group='products-services', entity_type='TOPC'), Topic(id='business,assets,facility-construction,,', name='Facility Construction', volume=131, description='A new facility is under construction', topic='business', topic_group='assets', entity_type='TOPC'), Topic(id='business,revenues,revenue-guidance,up,', name='Revenue Guidance Up', volume=129, description='Sales figures are forecast to rise', topic='business', topic_group='revenues', entity_type='TOPC'), Topic(id='society,reputation,apology,,', name='Apology', volume=125, description="An expression of regret or remorse for one's actions", topic='society', topic_group='reputation', entity_type='TOPC'), Topic(id='business,analyst-ratings,analyst-ratings-change,positive,', name='Analyst Ratings Change Positive', volume=125, description='A stock rating is upgraded', topic='business', topic_group='analyst-ratings', entity_type='TOPC'), Topic(id='society,cyber-security,cyber-attacks,,', name='Cyber Attacks', volume=124, description='A malicious attempt to breach the information system of an individual or organization', topic='society', topic_group='cyber-security', entity_type='TOPC'), Topic(id='business,products-services,product-support,discontinued,', name='Product Support Discontinued', volume=119, description='A company pulls support for an application or feature related to a product', topic='business', topic_group='products-services', entity_type='TOPC'), Topic(id='business,equity-actions,ownership,decrease,', name='Ownership Decrease', volume=119, description='A company decreases its investment in another company', topic='business', topic_group='equity-actions', entity_type='TOPC'), Topic(id='business,revenues,revenue-guidance,,', name='Revenue Guidance', volume=119, description='Projected sales figures', topic='business', topic_group='revenues', entity_type='TOPC'), Topic(id='business,stock-picks,stock-pick,,', name='Stock Pick', volume=112, description='An analyst gives a recommendation on a stock', topic='business', topic_group='stock-picks', entity_type='TOPC'), Topic(id='business,price-targets,price-target,set,', name='Price Target Set', volume=108, description='An analyst issues an estimate of the future price of a security', topic='business', topic_group='price-targets', entity_type='TOPC'), Topic(id='business,industrial-accidents,automobile-accident,,', name='Automobile Accident', volume=106, description='An accident occurs involving an automobile', topic='business', topic_group='industrial-accidents', entity_type='TOPC'), Topic(id='economy,taxes,import-tax,,', name='Import Tax', volume=100, description="Tax levied on imported goods by a country's customs authorities", topic='economy', topic_group='taxes', entity_type='TOPC'), Topic(id='business,revenues,revenue,below-expectations,', name='Revenue Below Expectations', volume=96, description='Sales figures are weaker than forecast', topic='business', topic_group='revenues', entity_type='TOPC'), Topic(id='business,labor-issues,hirings,,', name='Hirings', volume=94, description='Recruitment of new employees', topic='business', topic_group='labor-issues', entity_type='TOPC'), Topic(id='business,revenues,revenue-guidance,down,', name='Revenue Guidance Down', volume=94, description='Sales figures are forecast to fall', topic='business', topic_group='revenues', entity_type='TOPC'), Topic(id='society,legal,verdict,,', name='Legal Verdict', volume=90, description='The decision given by the jury or judge at the end of a trial', topic='society', topic_group='legal', entity_type='TOPC'), Topic(id='business,equity-actions,fundraising,,', name='Fundraising', volume=90, description='A company secures a new funding round', topic='business', topic_group='equity-actions', entity_type='TOPC'), Topic(id='business,products-services,demand,increase,', name='Demand Increase', volume=90, description='Demand for goods and services rises', topic='business', topic_group='products-services', entity_type='TOPC'), Topic(id='business,earnings,earnings-per-share,positive,', name='Earnings Per Share Positive', volume=90, description='Earnings per share results show a net profit', topic='business', topic_group='earnings', entity_type='TOPC'), Topic(id='business,bankruptcy,bankruptcy,,', name='Bankruptcy', volume=76, description='Legal proceeding initiated when unable to repay outstanding debts or obligations', topic='business', topic_group='bankruptcy', entity_type='TOPC'), Topic(id='business,labor-issues,executive-salary,,', name='Executive Salary', volume=71, description="Total value of an executive's pay", topic='business', topic_group='labor-issues', entity_type='TOPC'), Topic(id='business,earnings,earnings-guidance,down,', name='Earnings Guidance Down', volume=71, description='Earnings results are forecast to decrease', topic='business', topic_group='earnings', entity_type='TOPC'), Topic(id='business,assets,facility,close,', name='Facility Close', volume=69, description='A facility is temporarily or permanently closed', topic='business', topic_group='assets', entity_type='TOPC'), Topic(id='business,earnings,earnings-guidance,,', name='Earnings Guidance', volume=69, description='Projected earnings results', topic='business', topic_group='earnings', entity_type='TOPC'), Topic(id='economy,taxes,import-tax,increase,', name='Import Tax Increase', volume=66, description='Import tax rates rise', topic='economy', topic_group='taxes', entity_type='TOPC'), Topic(id='business,products-services,project-abandoned,,', name='Project Abandoned', volume=65, description='A project is canceled', topic='business', topic_group='products-services', entity_type='TOPC'), Topic(id='business,products-services,regulatory-product-approval,granted,', name='Regulatory Product Approval Granted', volume=62, description='A product receives approval to be developed, marketed or used', topic='business', topic_group='products-services', entity_type='TOPC'), Topic(id='business,equity-actions,public-offering,,', name='Public Offering', volume=61, description="Offering of a company's securities to public markets", topic='business', topic_group='equity-actions', entity_type='TOPC'), Topic(id='business,regulatory,regulatory-investigation,completed,', name='Regulatory Investigation Completed', volume=60, description='An investigation by a regulatory body is concluded', topic='business', topic_group='regulatory', entity_type='TOPC'), Topic(id='business,products-services,supply-guidance,increase,', name='Supply Guidance Increase', volume=59, description='Production levels are forecast to rise', topic='business', topic_group='products-services', entity_type='TOPC'), Topic(id='business,assets,facility,upgrade,', name='Facility Upgrade', volume=59, description='A facility is enhanced', topic='business', topic_group='assets', entity_type='TOPC'), Topic(id='business,stock-prices,market-capitalization,,', name='Market Capitalization', volume=56, description="Total value of a company's outstanding shares of stock", topic='business', topic_group='stock-prices', entity_type='TOPC'), Topic(id='society,cyber-security,malware-attack,,', name='Malware Attack', volume=55, description="A cyberattack where malicious software executes unauthorized actions on the user's system", topic='society', topic_group='cyber-security', entity_type='TOPC'), Topic(id='business,products-services,market-exit,,', name='Market Exit', volume=55, description='A company pulls out of a market or industry', topic='business', topic_group='products-services', entity_type='TOPC'), Topic(id='business,labor-issues,executive-firing,,', name='Executive Firing', volume=50, description='An executive is suspended or dismissed', topic='business', topic_group='labor-issues', entity_type='TOPC'), Topic(id='business,products-services,demand,,', name='Demand', volume=50, description='Quantity of goods and services that consumers are willing to buy at a specific price', topic='business', topic_group='products-services', entity_type='TOPC'), Topic(id='business,marketing,product-promotion,,', name='Product Promotion', volume=50, description='A product or service is on sale', topic='business', topic_group='marketing', entity_type='TOPC'), Topic(id='business,analyst-ratings,analyst-ratings-change,negative,', name='Analyst Ratings Change Negative', volume=49, description='A stock rating is downgraded', topic='business', topic_group='analyst-ratings', entity_type='TOPC'), Topic(id='society,legal,copyright-infringement,,', name='Copyright Infringement', volume=46, description='Unauthorized use, reproduction, distribution, or display of copyrighted works', topic='society', topic_group='legal', entity_type='TOPC'), Topic(id='business,business-operations,business-operations-resumed,,', name='Business Operations Resumed', volume=43, description='Business activity resumes after operational disruptions', topic='business', topic_group='business-operations', entity_type='TOPC'), Topic(id='business,products-services,market-share,,', name='Market Share', volume=42, description="Percentage of a market's total sales controlled by a company or product", topic='business', topic_group='products-services', entity_type='TOPC'), Topic(id='business,assets,facility,sale,', name='Facility Sale', volume=41, description='A facility is sold', topic='business', topic_group='assets', entity_type='TOPC'), Topic(id='business,acquisitions-mergers,acquisition-bid,interest,', name='Acquisition Interest', volume=38, description="A company is in talks to purchase most or all of another company's shares", topic='business', topic_group='acquisitions-mergers', entity_type='TOPC'), Topic(id='business,acquisitions-mergers,merger,failed,', name='Merger Failed', volume=37, description='A company abandons plans to merge with another company', topic='business', topic_group='acquisitions-mergers', entity_type='TOPC'), Topic(id='economy,consumption,vehicle-sales,down,', name='Vehicle Sales Down', volume=36, description='Car sales decrease', topic='economy', topic_group='consumption', entity_type='TOPC'), Topic(id='business,products-services,demand,decrease,', name='Demand Decrease', volume=36, description='Demand for goods and services falls', topic='business', topic_group='products-services', entity_type='TOPC'), Topic(id='business,products-services,business-contract,terminated,', name='Business Contract Terminated', volume=34, description='A company ends an agreement with another company', topic='business', topic_group='products-services', entity_type='TOPC'), Topic(id='business,analyst-ratings,analyst-ratings-coverage,initiated,', name='Analyst Ratings Coverage Initiated', volume=34, description='Analyst coverage is initiated on a stock', topic='business', topic_group='analyst-ratings', entity_type='TOPC'), Topic(id='business,products-services,government-contract,terminated,', name='Government Contract Terminated', volume=33, description='A government contract ends', topic='business', topic_group='products-services', entity_type='TOPC'), Topic(id='business,exploration,resource-discovery,,', name='Resource Discovery', volume=32, description='A new commodity deposit or zone is discovered', topic='business', topic_group='exploration', entity_type='TOPC'), Topic(id='business,equity-actions,initial-public-offering,,', name='Ipo', volume=29, description='A company first sells shares of stock to the public', topic='business', topic_group='equity-actions', entity_type='TOPC')])
('people', [Person(id='CE464B', name='Elon Musk', volume=46430, description='Elon Reeve Musk (born June 28, 1971) is a South African-born Canadian-American entrepreneur and business magnate who has served as the Chief Executive Officer of Tesla Inc. since October 2008 and previously held the position of Chairman from April 2004 to November 2018, also being a co-founder of the company. He is also the CEO, CTO, and founder of Space Exploration Technologies Corp. (SpaceX) since June 2002. Musk also founded X Corp. in March 2023, where he initially served as Chief Executive Officer until June 2023, subsequently taking on the roles of Chairman and Chief Technology Officer.', entity_type='PEOP', position='Chief Executive Officer', employer='Tesla Inc.', nationality='American', gender='Male'), Person(id='22C3AF', name='Donald Trump', volume=14612, description='Donald Trump (born June 14, 1946) is an American business owner and politician. Since January 20, 2025, he has been the 47th president of the United States. He previously served as the 45th president from 2017 to 2021. He is also the chairman and president of The Trump Organization.', entity_type='PEOP', position='President', employer='Government of the United States', nationality='American', gender='Male'), Person(id='B3F6B3', name='Satya Nadella', volume=1902, description="Satya Narayana Nadella Chowdary (born 1967) is an Indian-American business executive, currently serving as the CEO of Microsoft since 2014 and as Chairman since 2021. He is known for his leadership in transforming the company's focus towards cloud computing and artificial intelligence.", entity_type='PEOP', position='Chief Executive Officer', employer='Microsoft Corp.', nationality='American', gender='Male'), Person(id='A36J1C', name='Dan Ives', volume=499, description='Dan Ives is a Managing Director at Wedbush Securities, Inc. and previously held the position of Managing Director at FBR Capital Markets & Co.', entity_type='PEOP', position='Head of Equity Research', employer='Wedbush Securities Inc.', nationality=None, gender=None), Person(id='F53E60', name='Bill Gates', volume=244, description='William Henry "Bill" Gates, III is an American business magnate, philanthropist, investor, computer programmer, and inventor. He co-founded Microsoft Corporation and served as its CEO and chairman from 1975 to 2000, making him one of the most influential figures in the technology industry.', entity_type='PEOP', position='Co-Founder', employer='Microsoft Corp.', nationality='American', gender='Male')])
to_dict(). Let’s display all Objects related to the query of type products:import pandas as pd
co_mentions_dic = co_mentions.to_dict()
pd.DataFrame(co_mentions_dic['products'])
Why does it return different volumes in two Object that I added in the query?
Why does it return different volumes in two Object that I added in the query?
Let’s explore an example of a query with two Entity filters and an Output: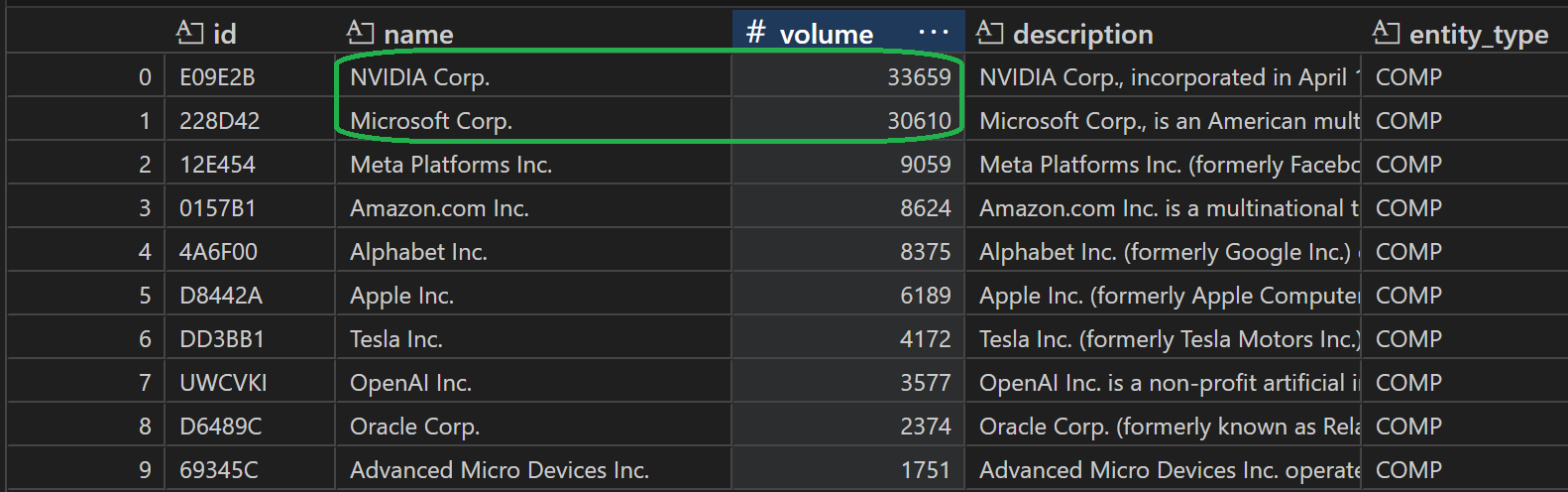
& operator:Example:from bigdata_client import Bigdata
from bigdata_client.daterange import AbsoluteDateRange
# Entity IDs
NVDA = "E09E2B"
MICROSOFT = "228D42"
bigdata = Bigdata()
date_range = AbsoluteDateRange("2025-01-01T00:00:00", "2025-05-01T00:00:00")
query = Entity(NVDA) & Entity(MICROSOFT)
search = bigdata.search.new(query=query, date_range=date_range)
co_mentions = search.get_comentions()
co_mentions_dic = co_mentions.to_dict()
pd.DataFrame(co_mentions_dic['companies'])
33658 chunks and Microsoft in 30609 chunks, even though the query stated an AND operation with both Entities. We get this effect because a chunk can also pass the query criteria if the entity is identified in the document’s headline but not in the chunk.The goal of co-mentions is to answer the following question:- What other Objects are mentioned the most in my search?