Documentation Index
Fetch the complete documentation index at: https://docs.bigdata.com/llms.txt
Use this file to discover all available pages before exploring further.
Overview
The Bigdata Content API lets you manage and query private content that you or your organization uploads to Bigdata, making it available for the Search and Research Agent after enrichment and indexing. You can onboard content in two ways:- Connectors API: For asynchronous, unsupervised, or automated workflows where content is not directly accessible by the user (e.g. email inbox, broker investment research feeds, SharePoint). You configure a connector and the service ingests the content from that source.
- Direct upload (POST /documents): For clients that manage their own corpus and want to build the ingestion workflow manually. You request a pre-signed URL and document id; you upload each file via PUT to that URL, then use the id to poll for enrichment status. The workflow uploads your document, enriches it (extraction, structure and annotation of the content), and indexes it for availability in Search and Research Agent.
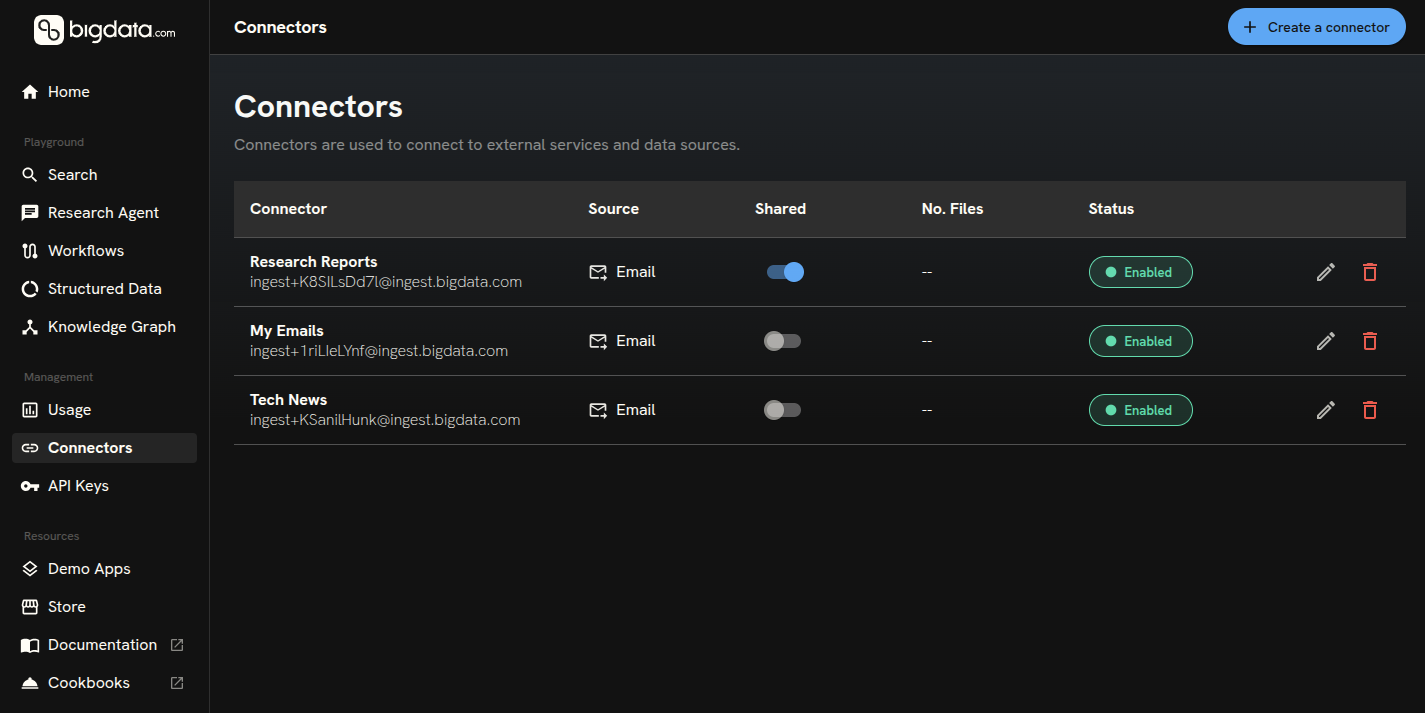
Connectors
Connectors are for ingestion that is asynchronous, unsupervised, or part of a workflow where content is not directly in the user’s hands, for example, an email inbox, a broker investment research feed, or a SharePoint library.- You create a connector with a type, label, and type-specific configuration. Supported types include Email Inbox, Investment research, and (coming soon) Microsoft SharePoint.
- For Email, the API returns an inbox address; you forward messages from allowed senders to that address. Set up automatic forwarding rules in your email client to start building your corpus, Bigdata will ingest and process content automatically.
- For Investment research, provide broker credentials when you create the connector. Bigdata then syncs research documents from the broker for you. Ingested documents are tagged with the broker name and classified using Bigdata’s document taxonomy, so you can filter and search them consistently alongside the rest of Bigdata corpus.
- Content arriving through the connector is turned into documents you can manage and use via Search and Research Agent Services.
- Create connector: Register a new ingestion source. For email connectors, the response includes a connector ID and an inbox address; forward messages from allowed senders to that address to ingest content into Bigdata. For
investment_research, supply brokeruser_idanduser_passwordinconfig. - List connectors: List all connectors you can access; use connector IDs to filter documents or to update/delete.
- Get connector: Fetch full details for one connector (config, share settings, timestamps).
- Update connector: Change label, description, sharing, or configuration of the connector.
- Delete connector: Soft-delete (archive) a connector by default—it stops ingesting new content but existing documents remain. Use
?force_delete=trueto trigger a hard delete: all files related to the connector are deleted asynchronously, then the connector is removed from the database.
Documents
Documents are the items Bigdata has uploaded, enriched, and indexed for search and analysis, whether they came from a connector (e.g. email, SharePoint) or from direct upload. Direct upload is intended for clients that manage their corpus and want to build the ingestion workflow from scratch: you choose what to send, when, and with what metadata (file name, tags, sharing). The main focus is enrichment: once you upload the file (PUT to the pre-signed URL), Bigdata enriches it (extraction, structure and annotation of the content), then indexes it for availability in Search and Research Agent. Use Enrich document to get a pre-signed URL and document id; PUT the file to that URL, then use the id with Get document metadata to poll for status until enrichment and indexing are complete. The following operations apply to all documents, whether they were ingested via a connector or direct upload:- List documents: Paginated list of documents you can access. Supports filtering and sorting (including
originvaluesemail,investment_research, andfile_upload); each item includes a content ID for use with the other document endpoints. - Get document metadata: Return metadata for one document by content ID (status, file name, connector, tags, timestamps). Use this to check enrichment status before downloading content.
- Get annotated document: Return a time-limited pre-signed URL. GET that URL to download private document content as structured JSON (metadata, title, body blocks, entities, sentences with sentiment). Use for search indexing, entity extraction, or structured display.
- Get original document: Return a time-limited pre-signed URL. GET that URL to download the private document’s original file in its native format (e.g. .eml, .pdf).
- Delete document: Remove a document from the platform. Deletes the original document, annotated version, and chunks from the vector database.
broker:Broker Name for investment research. Use List tags to discover tag names, then use them to filter via Search Service or Research Agent.
Typical flow
Using connectors (async / unsupervised):- Create a connector (e.g. email) with type, label, and config; for email, use the returned inbox address to forward messages.
- Optionally check that content has been enriched and indexed by listing your recent documents.
- Use your content in the Search or Research Agent Service (e.g. filter by Emails in the playgrounds below).
- Call Enrich document with metadata (file name, tags, sharing); use the returned URL to PUT the file (upload it).
- Poll Get document metadata with the returned id to check
statusuntil enrichment and indexing are complete (completed). See Get document metadata in the API reference. - Use your content in the Search or Research Agent Service (e.g. filter by My Files in the playgrounds below).
Search Service Playground
Search across your private content and other sources. In the playground, open the source selector and choose My Files to limit results to your uploaded documents.
Research Agent Playground
Run research over your private content and real-time data. In the playground, use the source selector and filter by My Files to ground answers in your documents.
Authentication and reference
All endpoints require an API key sent in theX-API-KEY header. See Authentication for details.
Use the API reference (endpoints listed in this section) for request/response schemas, parameters, and examples. You can try the API from the Developer Platform playgrounds.